
昨天完成了一條「數據淘金」流水線,從指定的RSS白名單中篩選、抓取並清洗出純淨的文字內容,手上已經有了自己篩選過的資料來源。
今天將在n8n裡加入AI大腦,大型語言模型 (LLM),指示它將那些長篇大論的文章,提煉成我們App所需的內容,含摘要和標籤。
步驟一:選擇你的AI大腦 —— OpenAI(GPT) vs. Google(Gemini)
目前市面上最主流、開發者整合最方便的,是OpenAI的GPT系列和Google的Gemini系列。
優勢: API成熟穩定,社群龐大,文件資源豐富,尤其是 gpt-3.5-turbo模型,在速度、成本和遵循指令(產生JSON)取得絕佳的平衡,非常適合我們的專案。
考量: 需要註冊並綁定付費方式才能獲取 API 金鑰。
優勢: 透過 Google AI Studio 提供相當慷慨的免費額度,模型能力強大,特別是在多模態能力上。
考量: 對於開發者來說,API的普及度和社群範例可能略少於OpenAI,且使用上會有延遲,偶爾可能需要排隊等候使用。
我將使用Gemini 2.5 Flash模型,之後依使用需求可以再移到任何其他主流LLM上。
在n8n中設定憑證,先到Google AI Studio取API Key,再依序Credentials > Add credential > API Key 貼上,現在n8n就擁有了呼叫LLM大腦的權限了。
步驟二:溝通藝術 —— 設計驅動AI行為的Prompt
與LLM溝通的關鍵,在於設計一份好的提示詞(Prompt),像是工作說明書,用來指導AI完成我們的任務,但由於我是免費使用,使用上就有延遲了,先以以下重點為主,之後邊做邊改良細節。
步驟三:連接神經元 —— 在n8n中實現AI摘要工作流
在Day 3最後的Clean & Finalize節點後,新增Message a model節點,將上面自己設計好的完整Prompt範本貼到Message欄位中。
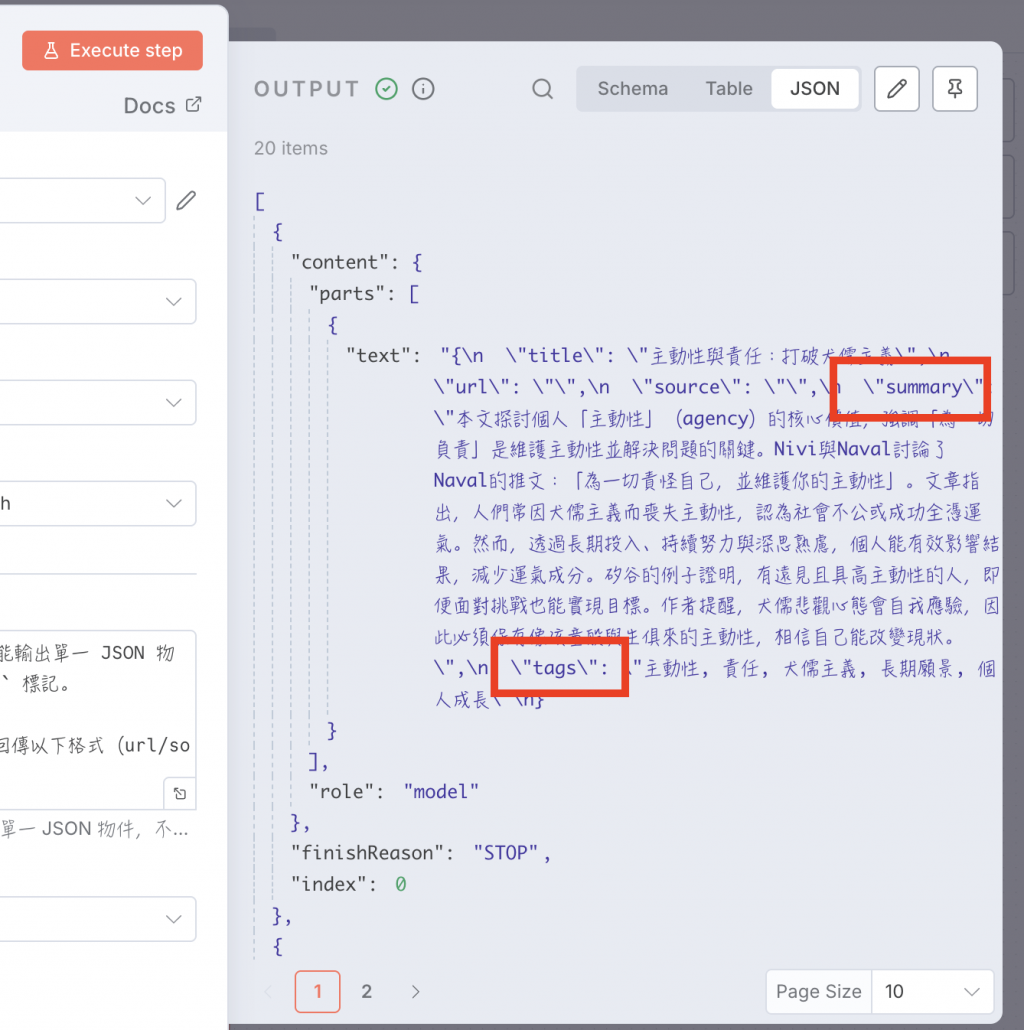
執行後,會發現 summary 和 tags 已經被成功提取出來,成為獨立的數據欄位了!(我會慢慢把細節補回前面的文章,不好意思 )
)
今天完成了LLM的串接,使n8n不再只是數據的搬運工,可以藉由文章摘要,給予創作者靈感,明天將繼續優化此工作流,並在結尾建立Webhook API,好傳遞給我們即將誕生的 Flutter App。Day 5 見!
【哈囉你好:)感謝你的閱讀!其他我會常出沒的地方:Threads】
